What is “Big Data” — Understanding the History
A tour through history, how we ended up here, what capabilities we’ve unlocked, and where we go next?
How It All Began (1940s)
A long time ago, in December 1945, the first electronic general-purpose digital computer was completed. It was called ENIAC (Electronic Numerical Integrator and Computer). It marked the start of an era where we produced computers for multiple classes of problems instead of custom building for each particular use case.
To compare the performance, ENIAC had a max clock of around 5 kHz on a single core, while the latest chip in an iPhone (Apple A13) has 2.66 GHz on 6 cores. This roughly translates to about four million times more cycles in a second, in addition to improvements in how much work can be accomplished in one of those cycles.
Historically, we’ve gone through cycles of expanding on the newest hardware advances to unlock new software engineering capabilities. There has been a pattern of increasing flexibility while also requiring more responsibility from the engineers. Inevitably there is a desire to reduce the additional burden that the engineers take while providing the same flexibility. This flexibility is enabled by implementing best practices that get teased out as we understand the patterns that work within a particular abstraction.
The Evolution of Data (1960s-1990s)
Historically servers were costly with limited storage, memory, and compute capabilities to solve the problems we wanted to solve without significant effort by the programmers such as memory management. In contrast, today, we now have languages with automated garbage collection to handle this for us. This is why C, C++, and FORTRAN were used so much and continue to be used for high-performance use cases where we try and drive as much efficiency and value out of a system as possible. Even today, most data analytics and Machine Learning frameworks in Python call out to C to ensure performance and only expose an API for the programmer.
To extract as much value as possible out of systems organizing data, companies like IBM invested heavily in particular models for storing, retrieving, and working with data. We have the hierarchical data model that was extremely prevalent during the days of big metal in the mainframe from this work. By creating a standard model, they reduced the amount of mental effort required to get a project started and increased knowledge that could be shared between projects.
Mainframes worked for the day’s problems but were prohibitively expensive, so only the largest enterprises such as banks were able to leverage them effectively. They were very efficient in traversing tree-like structures, but they imposed a very strict one-to-many relation that could be difficult to express for the programmer and make their applications hard to change.
Later on, the relational model was created, which powers most of our databases today. In the relational model, data is represented as sets of tuples (tables) with relations between them. A typical relationship is a foreign key which says that data in two tables should be related to each other. You can’t have a grade without a student to tie it to, and you can’t have a class without a teacher to teach the lesson.
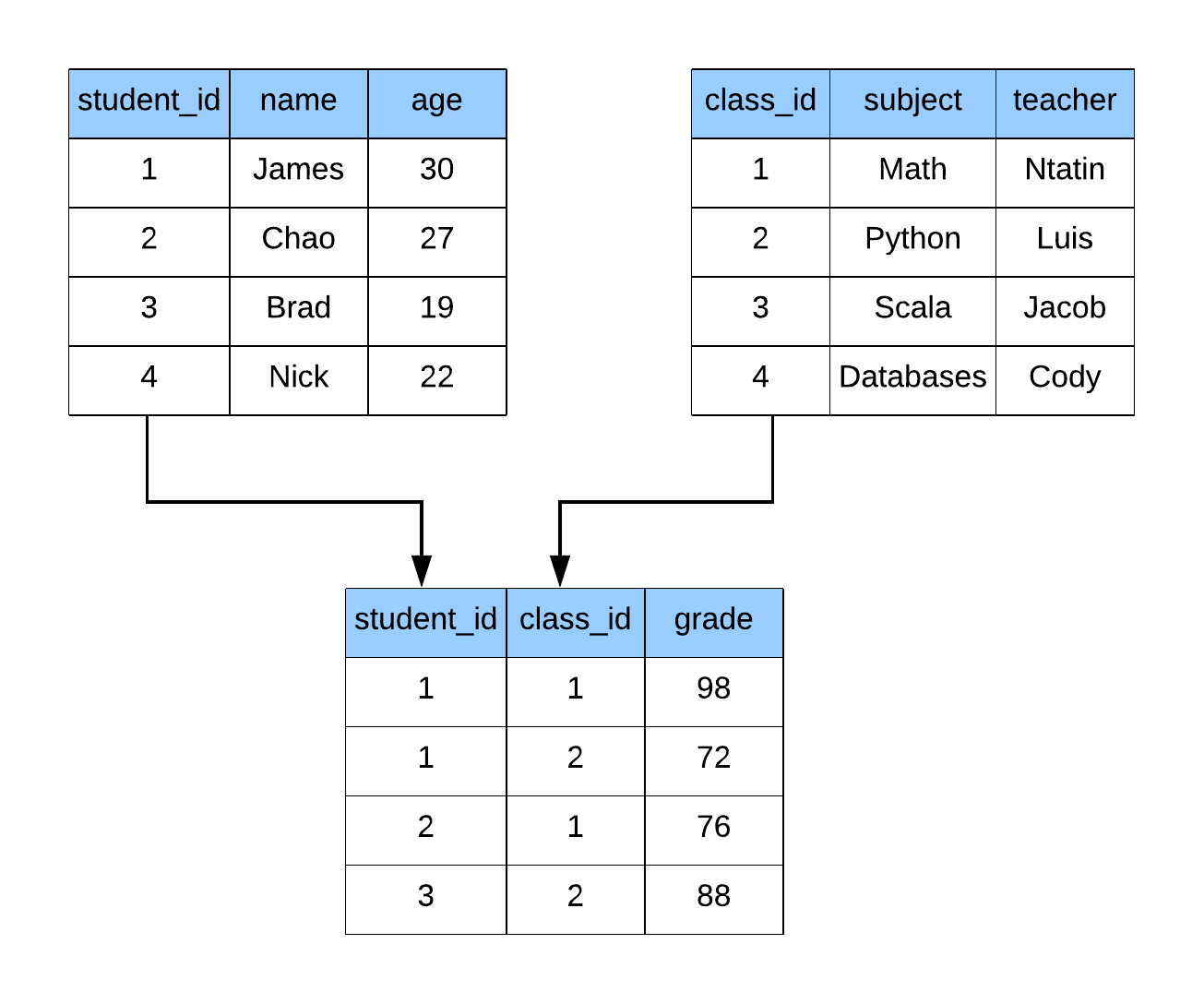
Due to the structure that is applied to the data, we can define a standard language to interact with data in this form. The original inventor of the Relational Model also created its Structured Query Language (SQL), which is the de-facto standard for accessing data today. This is because SQL is easy to read, while also being extremely powerful. SQL is even Turing complete when the system has capabilities for recursion and windowing functions. Turing completeness roughly translates to the language can solve any computational problem given enough time. That’s an excellent theoretical property of SQL, but it doesn’t always mean it is the best tool for every job. This is why we use SQL to access and retrieve data, but leverage Python and other languages to do advanced analytics against the data.







